Compression Architecture for Bit-write Reduction
Compression Architecture for Bit-write Reduction in Non-volatile Memory Technologies(原文链接)。本文提出了一个基于压缩的架构,实现位写减少。位写减少有很多的好处,包括降低写延迟、降低动态功耗、提高耐受力。提出一个集成进NVM模块的架构,包括(i)一个频繁模式压缩-解压引擎;(ii)和一个比较器协同工作实现减少位写;(iii)一个投机取巧的磨损均衡方案,通过减少部分cell位反复写,平衡分布写,提高内存的耐受力。
Compression-based NVM
本文描述的压缩架构的核心思想是内存中word被一个new word重写的时候,利用一个简单的压缩方案来减少位写。目前最先进的针对这部分的研究有DCW和FNW。与DRAM不同,DRAM在每次读写操作期间,所在的整个内存行需要被写回。而在NVM中,刷新没有发生变化的位没有必要。
Write
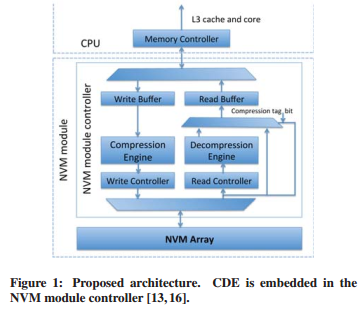
集成了本文架构的NVM模块如何处理写请求?首先,直接集成在NVM模块中的CDE(Compression-Decompression Engine)尝试压缩写入的新数据,CDE实现了基于FPC(见上篇博客)的压缩方法。然后,当CDE尝试压缩数据的同时,NVM模块控制器读取NVM数组中目标地址的数据(旧数据)。一旦压缩完成,旧数据和新数据逐位比较找不同位,否则,直接写入未压缩数据。基于逐位比较结果,只更新写入新旧数据之间对应不同的位(差分写)。最后,系统更新压缩tag位,来表明该地址的数据是否被压缩。
Read
在读访问过程中,执行步骤和写数据相反。首先,CDE从NVM数组读取word及其对应的tag位。检查tag位确定读取的word是否被压缩,若被压缩,该word经过CDE,解压结果直接转发到处理器。否则,该word略过CDE组件,直接被转发到处理器。
Architecture
如下图所示,CDE直接集成到NVM模块,实现数据在写操作期间的无缝压缩与解压。添加额外的电路,实现新数据经过CDE,允许未压缩的数据在读操作期间绕过CDE被读取。NVM阵列也相应地修改,以支持tag位标记是否压缩和磨损均衡。NVM阵列中每个32-bit word,添加两个tag位,一个tag用于表示内存中数据是否被压缩,另一个tag用于磨损均衡技术中表示“normal”写还是“flip”写。这里的tag位带来的额外存储开销与FNW方案中一样,FNW中每16-bit要求1个tag。
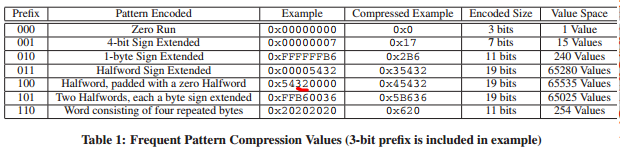
Frequent Pattern Compression(FPC)
写访问期间,CDE压缩写入的新数据时,利用基于FPC的压缩方法,首先检查word的内容,确定是否匹配FPC模式表中的某种模式,如果匹配,CDE添加相应前缀压缩编码该word。读访问期间,这个3-bit的前缀用来确定匹配的模式,CDE可以根据模式表反向解码该word。
如下图写入新数据,对应上图模式表中001的4-bit符号扩展模式,因此新数据压缩编码为前缀+数据,即0011001,若从左往右逐位与旧数据进行比对,翻转写不同位,如图所示标红有两bit翻转写。到这里很容易考虑到一个问题,如果每次写入新数据的时候都这样操作,那么位翻转全部集中在word的左侧bit,会造成写入不均衡的问题,怎么解决?很简单,适当地从右往左写,但是这样的话,同样会有问题,对于利用FPC压缩效果不佳(大部分word压缩率不足50%)的应用,比如32-bit压缩至加上前缀共19bit,那么中间有6-bit重叠,无论从左还是从右写都一样,中间6bit都会受到磨损,这会造成word中间部分bit的重复写,最终导致word中间部分bit最先磨损。同样,若压缩效果太好的话,中间bit位无论从哪边开始写都不被磨损,会造成word的中间部分bit翻转写次数极少。
这个问题带来的影响本文没有很好地解决!!!
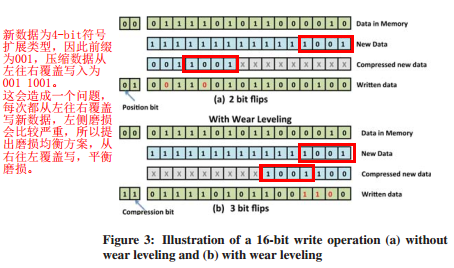
Wear Leveling
针对以上磨损均衡方案,CDE和NVM阵列需要做必要的修改。
Write
每个word添加第二个“position” tag位,表示当前将数据存储到NVM阵列的哪一侧。与此同时,NVM模块添加电路,来决定压缩数据应该正常写还是翻转写,tag为0表示正常写(从左往右),tag为1表示翻转方向对称写(从右往左)。此外,如果被写入的新数据没有匹配上任何模式,即未被压缩,那么position tag位为0,因为对于未压缩数据,数据从哪一侧写都一样。
Read
读访问期间,如果数据是压缩的,CDE读取position tag位,确认数据在NVM阵列的哪一侧。如果position tag位表示数据被写入NVM word的右半部分,那么CDE读取的数据将被翻转,以将前缀恢复到正确的形式,并将数据传递给CDE对应模式表进行解压缩。
Write orientation
那依据什么来决定在NVM阵列中新数据到底是从左向右写还是从右向左写呢?
本文提出有两个方法;
利用一个写访问计数器,一旦计数器超过某一固定阈值,写访问指示器由”normal”(即position tag为0)变为”flipped“(即position tag为1),转换写方向,并且重置计数器。
那么阈值怎么确定呢?
本文没说阈值的设定方式,本人感觉这个阈值应该小一点磨损均衡效果会更好,相当于更加频繁地在两个方向写之间切换,阈值越小,不会导致有一个方向的写入多一轮而多出的写次数比较多。使用翻转位写的数量来确定写的方向,实现一个更加投机取巧的磨损均衡方案。CDE中的附加电路比较新数据和旧数据,从两个方向进行比较。CDE基于这种比较,分别针对两个方向写计算出位翻转的数目,有更少位翻转的方向被选择,按该方向写入数据,同时正确设置position tag位。
但是第二种方法与其说是一种磨损均衡,似乎更像是一种翻转位写减少优化方案。同时也许可能有磨损均衡的作用,效果视数据类型而定吧。因为某些应用程序可能始终选择从左往右写,会得到更少的位翻转,这根本不能达到磨损均衡的目的。
Evaluation and Result
实验评估显示有几个负载翻转位写数量相比FNW反而增多,为什么?
实验发现,这些负载同时对应有较低的压缩率或者有很大比例的line不压缩,那么本文的方法由于增加的两个tag位也会带来额外的位翻转,可能会造成这种结果。
原文作者: malizhen
原文链接: http://malizhen.github.io/2019/07/04/Compression Architecture for Bit-write Reduction/
版权声明: 转载请注明出处(必须保留原文作者署名及原文链接)